


Os 3 vieses do desenvolvimento de software - Número 1: Estratificação
Dividir um software em camadas é uma boa ideia; desenvolver uma camada de cada vez, não é.

Recentemente, falei no Regional Scrum Gathering Stockholm sobre os 3 vieses do desenvolvimento de software: Estratificação, Cronologia e Modularidade.
O evento foi incrível, pois os organizadores (Evelyn, Giuseppe, Khurram e Thomas) e os voluntários fizeram um trabalho fantástico na organização. Saí do evento verdadeiramente feliz e com muito alimento para o pensamento. Essa foi minha motivação para transformar minha apresentação em três posts: um para cada viés que descrevi lá.
Então, o que são esses vieses?
Um viés pode ser definido como "Uma preferência ou inclinação, especialmente uma que inibe o julgamento imparcial". No desenvolvimento de software, isso poderia ser traduzido como modelar um projeto de software usando conceitos que estão profundamente enraizados em nosso cérebro, evitando assim uma abordagem alternativa que poderia nos ajudar a criar algo mais flexível.
Fazemos as coisas desta maneira porque sempre as fizemos assim. E isso é um loop infinito.
Para quebrar esses vieses, primeiro devemos entendê-los, então vamos começar com o primeiro: Estratificação.
Estratificação?
Sim, eu inventei esses três nomes e não estou realmente satisfeito com eles. Mas, como Phil Karlton disse: "Existem apenas duas coisas difíceis em Ciência da Computação: invalidação de cache e dar nomes às coisas".
O viés de estratificação acontece quando, após dividir um software em camadas (digamos: banco de dados, backend e frontend), começamos imediatamente a desenvolver a camada mais baixa, que geralmente é o modelo de banco de dados. Imagine isto: você começa com a camada de banco de dados, meticulosamente criando cada tabela e relacionamento. Só quando isso está "pronto" você passa para o backend, e que Deus o livre de alguém mencionar o frontend até que a API esteja completa!
Este é provavelmente o mais famoso dos vieses, pois há muito tempo é chamado de BDUF (Big Design Upfront) e foi uma das primeiras barreiras que tivemos que superar para desenvolver software mais flexível. A coisa triste é que ainda acontece. Muito.
Existem dois problemas principais com essa abordagem. Número um: efeitos colaterais. Uma mudança em um único ponto da camada superior pode gerar múltiplas mudanças nas camadas inferiores.
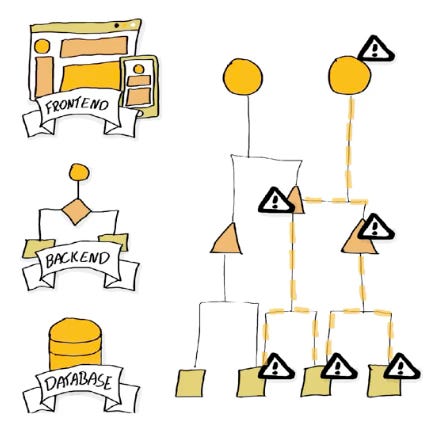
Segundo problema: efeitos colaterais dos efeitos colaterais, ou: bugs. Agora, porque você teve que mudar o banco de dados, alguma parte do backend que mal está relacionada à mudança inicial pode ser afetada e também afetar alguma parte do frontend que é completamente não relacionada à mudança inicial.
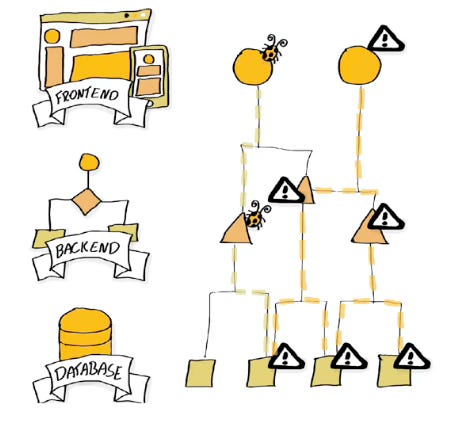
Se você prestou atenção, notou que ao corrigir um bug você poderia desencadear exatamente o mesmo processo novamente, o que nos leva a um loop infinito de desespero, frustração e clientes irritados.
Sou vítima desse viés? Como escapo dele?
Existem sintomas. Seu cliente não conseguirá fornecer feedback valioso porque não verá nada utilizável, a quantidade de retrabalho necessária sempre que você precisar mudar algo será insuportável, e você pode sentir a necessidade de descartar algumas boas ideias devido aos custos de desenvolvimento. Mais importante: seus desenvolvedores ficarão mortalmente entediados.
E justamente porque esse era o status quo não muito tempo atrás, os desenvolvedores entediados de então decidiram criar algo para ajudá-los a sair dessa situação. Algo que permitiria que o banco de dados evoluísse com segurança ao longo do tempo sem gerar muita dívida técnica. Eles chamaram isso de "Migrações de Banco de Dados".
É bonito, não é? Uma solução técnica criada para resolver um problema técnico que estava dificultando a capacidade da equipe de se adaptar às mudanças. Voltarei a isso mais tarde após o exemplo técnico, então se você já está familiarizado com o conceito ou não está familiarizado com código, pode pular a próxima seção.
Colocando a mão na massa (com código)!
Vamos dar uma olhada em uma Migração de Banco de Dados usando Elixir e Ecto. Imagine que você está criando uma tabela para armazenar os usuários do seu sistema. Você (e seu cliente) podem ter muitas ideias interessantes sobre todos os dados que você pode armazenar lá: nome, e-mail, uma pequena biografia, um avatar, data de nascimento, e a lista continua.
Se entendermos que o banco de dados pode evoluir, podemos começar com algo mais simples. Apenas o nome de usuário e o e-mail, por exemplo.
defmodule MyApp.Repo.Migrations.CreateUsers do
use Ecto.Migration
def change do
create table(:users) do
add :username, :string
add :email, :string
timestamps()
end
end
endFazer esta primeira parte nos fornecerá opções para a próxima iteração. Podemos realmente nos perguntar qual é a coisa mais importante a desenvolver: o avatar? a pequena biografia? algo completamente diferente em outra parte do sistema?
Mais tarde, se decidirmos implementar o avatar do usuário e uma biografia curtinha, poderíamos criar outra migração como esta:
defmodule MyApp.Repo.Migrations.AddProfileToUsers do
use Ecto.Migration
def change do
alter table(:users) do
add :bio, :text
add :avatar_url, :string
end
end
endDesta forma, podemos garantir que o banco de dados do cliente estará sempre atualizado e que ninguém executará o mesmo script de banco de dados duas vezes e quebrará tudo.
Existem benefícios técnicos, mas também não-técnicos
Além do benefício óbvio de criar algo mais flexível, existem alguns benefícios não-técnicos muito interessantes. Por exemplo: como você construiu um banco de dados mais leve, o que quer que a equipe precise desenvolver a seguir levará menos tempo simplesmente porque haverá menos campos e tabelas para lidar. Isso também se refletirá na quantidade de efeitos colaterais (ou seja, bugs) que seu processo de desenvolvimento pode gerar, porque a complexidade do seu software não crescerá exponencialmente como antes. Podemos resumir isso como: quebrar o viés de estratificação equivale a economizar tempo.
Esse tempo que você economizou pode gerar um efeito borboleta. A equipe agora pode pensar no que fazer com esse tempo. Talvez aprender a escrever alguns testes unitários, ou dedicar um tempo para experimentar uma nova tecnologia. Como a resposta a essa pergunta não é óbvia, eles terão que colaborar para encontrar a melhor opção. Observe que todos terão que colaborar: desenvolvedores, designers, testadores, pessoas de negócios.
Todo esse conceito de migração de banco de dados foi criado porque alguém desafiou a ideia de que "Não podemos alterar o banco de dados como quisermos". Uma pessoa técnica, com uma solução técnica. Porque às vezes, quando um desenvolvedor enfrenta um desafio como esse e tem o tempo e os recursos adequados para lidar com ele, uma inovação nasce.
Isso também acontece quando quebramos os vieses de Cronologia e Modularidade, mas falaremos sobre eles mais tarde. :)
Ps: Se você quiser ler mais sobre este assunto, pode conferir o post detalhado e incrível do Martin Fowler, aqui: https://martinfowler.com/articles/evodb.html