


The Pitfalls of AI Augmented Development - Part 1
Freshly written on the train back home

My talk on the Global Scrum Gathering Munich was fast, and I said there that I would write about the subject to go deeper into this discussion, so here I am. I added a "Part 1" to the title because right now I'd like to explore three of them: Written Fixation, Monolithic Approach and Atrophy to Learn.
The funny thing in this conference is that I went to two subsequent talks that directly connected to what I presented: Nigel Baker and Paul Goddard talked about Pair Programming (and I'm still disappointed they didn't mention Penn & Teller in their pairing examples) and the final keynote by Henrik Kniberg that talked about agentic AI in software and agile software development. So, I'll also connect insights from their presentations to enrich our conversation. To do that, I'll change the order in which I initially presented the pitfalls.
Pitfall 1 - Written Fixation
My first complaint about how most people have been using AI was about how we keep writing and using text as the only way to talk to our LLM's. Kniberg used two different forms of communication during his presentation: voice and a napkin drawing. And that's precisely what I was talking about: language has limitations, and these are old news. Nietzsche notoriously said that Every word is a prejudice and William James challenged our ability to comprehend the meaning behind the words with his squirrel going around the tree anecdote.
If you want to try how it could work, you can integrate Aider with ChatGpt to use your voice to program (and maybe that could be my next post as well). But if you don't want to go that far, draw, take screenshots to use as examples, basically: experiment.
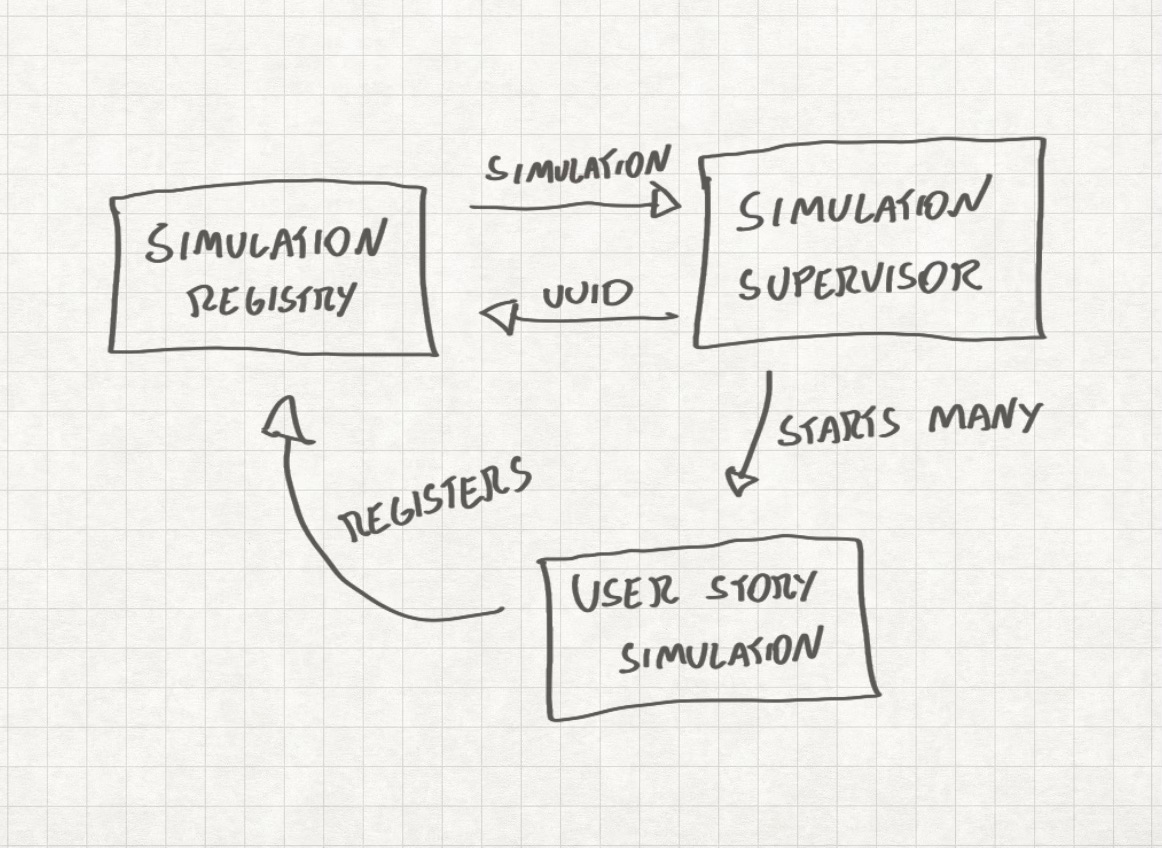
Now, the diagram immediately takes us to the next pitfall…
Pitfall 2 - Atrophy to Learn
If an AI can code, why would I learn to code? , well… that's an interesting question. In my talk I mentioned that the code generated by the current LLM's (like Sonnet 3.7) are actually pretty good, and often times better than what a human would write. And the LLM's are improving faster than we are right now, so…
So we still need to learn. Look at the diagram in the previous section: it talks about software structure and how to organize the code. If you don't know how to code, you can't come with diagrams like these and your options will be limited. These limitations can lead you to dead ends and problems you're unable to solve, and if your AI colleague is also unable to solve it then…
Like Nigel Baker and Paul Goddard said in their talk: pairing is a great way to learn. You will probably learn that different people use LLM's in different ways, and you'll have to figure out when to use each approach. For example: nowadays you can literally program an agent that would check everything your significant other posted on the internet and automatically buy them gifts at special dates. And they will probably be good gifts!
But is it a good idea? Well, I don't think so. Simon Wardley proposes an interesting question to solve this dilemma, and by all means, if you haven't watched his talk yet please do:
How much do you value a human involved in that decision?
And sometimes, when developing software, it matters. But then again: your decision making capabilities will be limited by your knowledge. So, keep learning (and try to pair with someone else so you can learn more and faster).
Pitfall 3 - The Monolithic Approach
I made a joke during my presentation and said that Vibe Coding should be renamed to Conversational Reactive Assisted Programming, or C.R.A.P.. Everybody laughed, and moments later we were all watching Henrik Kniberg doing an impressive demonstration using Cursor.
So, I think I'll have to explain myself. :)
The term Vibe Coding was coined by Andrej Karpathy, and he said that the technique is "not too bad for throwaway weekend projects". A key part of the definition of vibe coding is that the user accepts code without full understanding, and the AI researcher Simon Willison even said that "If an LLM wrote every line of your code, but you've reviewed, tested, and understood it all, that's not vibe coding in my book—that's using an LLM as a typing assistant.".
So, by that definition of Vibe Coding, I stand by my joke. At least for now. The concept of not caring about the code generated by an LLM can be a good idea, but only if we know when to use it, and for now it shouldn't be a 100% of the time unless you're building a prototype.
The thing is, if you don't know how to code, Vibe Coding will be your only option when using an LLM to develop software. And isn't really coding, because it's non-deterministic: the same prompt might generate different results. I prefer the term Simon Wardley uses: Vibe Wrangling.
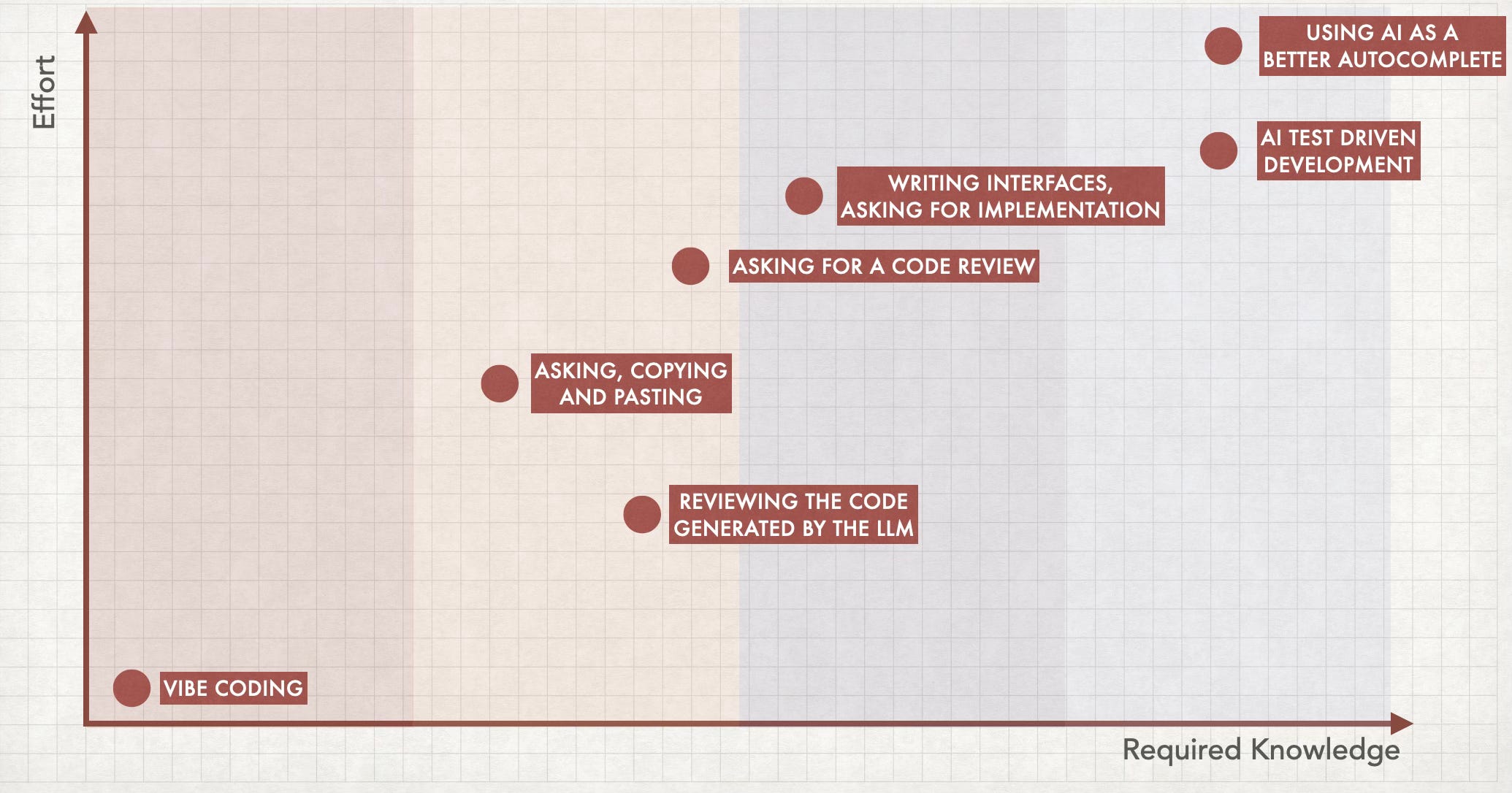
Maybe in the future having Vibe Coding as your only option won't be a problem, but we are not quite there yet. It might happen next year, in 2035, or it might never happen. But no matter the answer, learning to code is still relevant because it will expand your options. And that's my main (and maybe single) critique about Kniberg's great keynote session: I don't think that Vibe Coding is an evolution of copying and pasting code generated by an LLM, for example. I see all these approaches being used in different contexts, and the decision will always come down to a slightly modified version of the question proposed by Simon Wardley:
How conscious do I need to be about the way this is going to be implemented?
For me the answer is still "quite often". LLM's are biased, non-deterministic and they replicate all the problems that were present in their training data. They will make mistakes, and some of these mistakes might harm people, specially in groups that are under-represented in the data used to train the models (you can and should check Dr. Timnit Gebru’s work). When we accept AI-generated code without full understanding, we're inheriting not just the solution but also the conceptual prejudices embedded within it.
So, answering that question is something we'll start to do more and more. And going back to Nigel Baker and Paul Goddard's session: you don't have to answer that question alone.